New York Times API ETL
Descripción
This project implements an ETL (Extract, Transform, Load) process using Python to extract data from the New York Times API. The system collects news articles and performs processing to transform the information into a structured format suitable for analysis and storage in a database. The project encompasses the automation of data extraction, data cleansing and transformation, and final loading into an efficient storage system in a MySQL DataBase.


NYT Articles ETL Pipeline
This project implements an ETL (Extract, Transform, Load) pipeline to fetch, process, and store articles from The New York Times API.
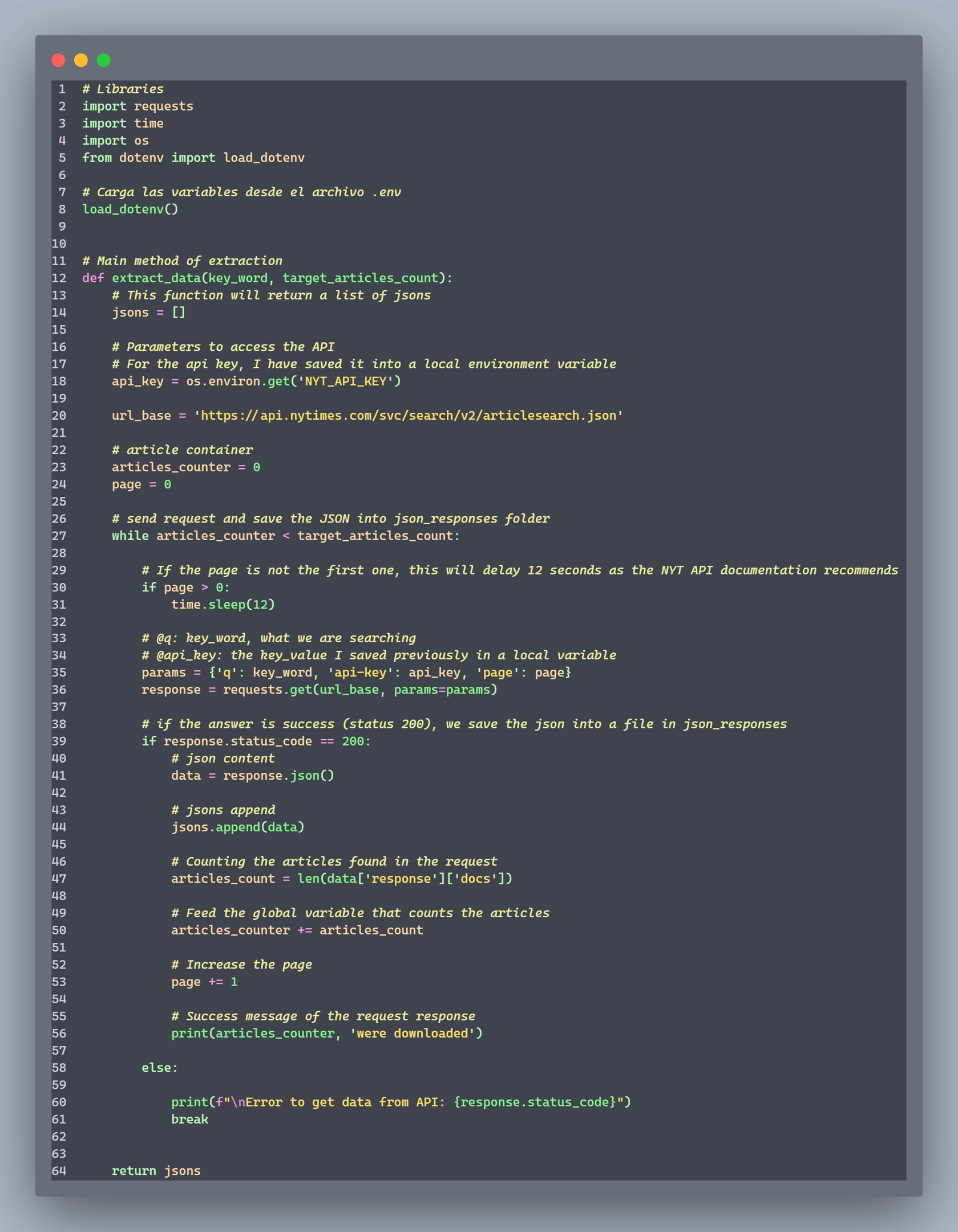
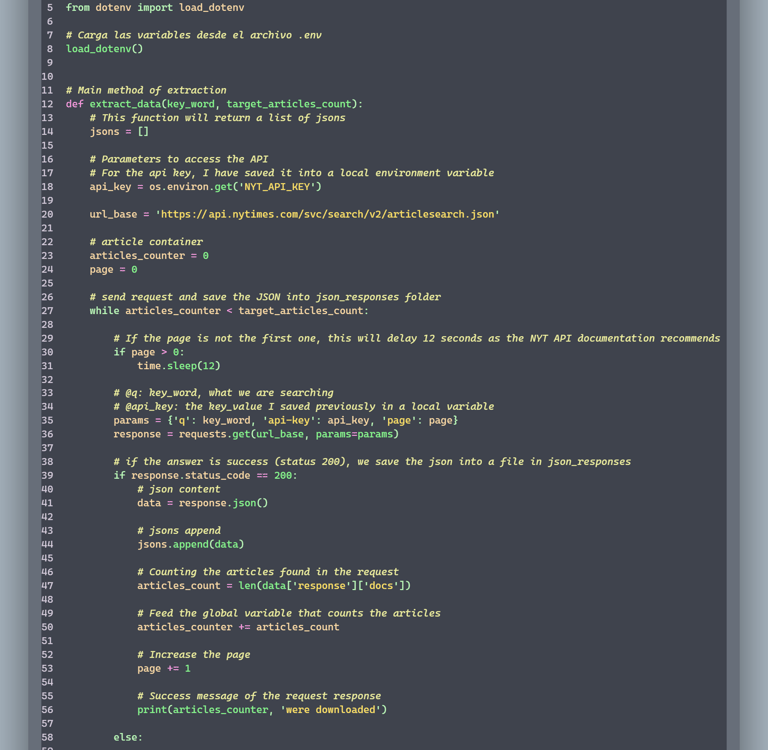
1. Extract (extract.py)
Makes requests to the New York Times API
Allows searching articles by keyword
Implements API rate limiting (12 seconds between requests)
Returns a list of JSONs containing article information
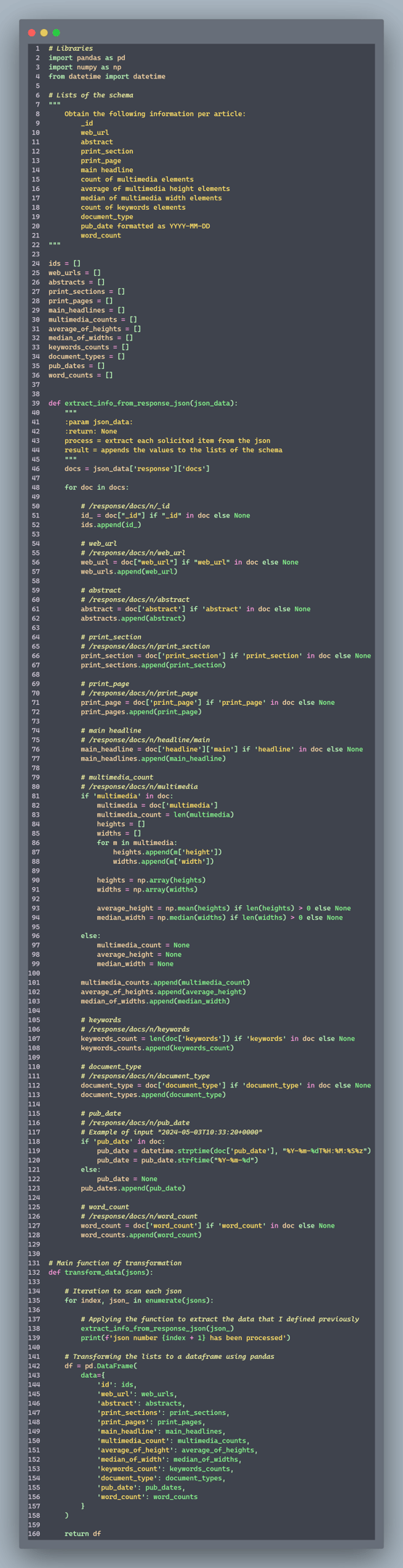
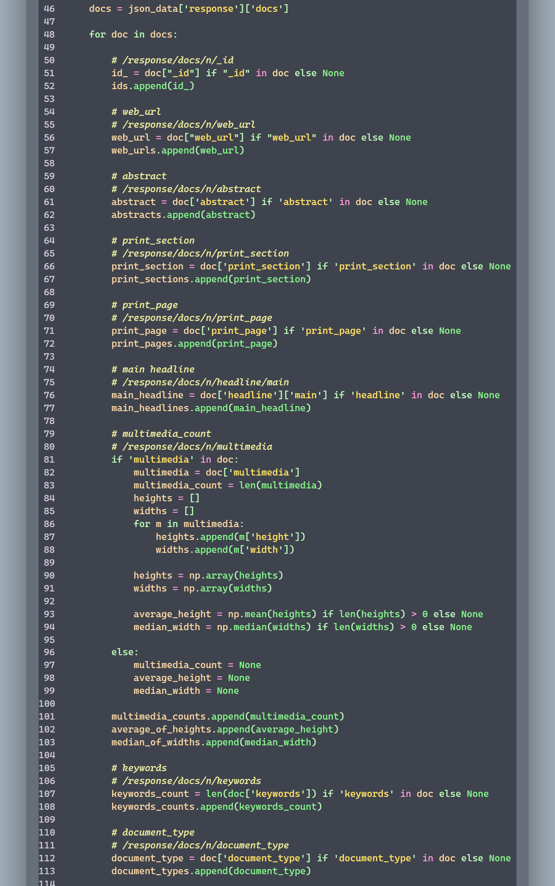
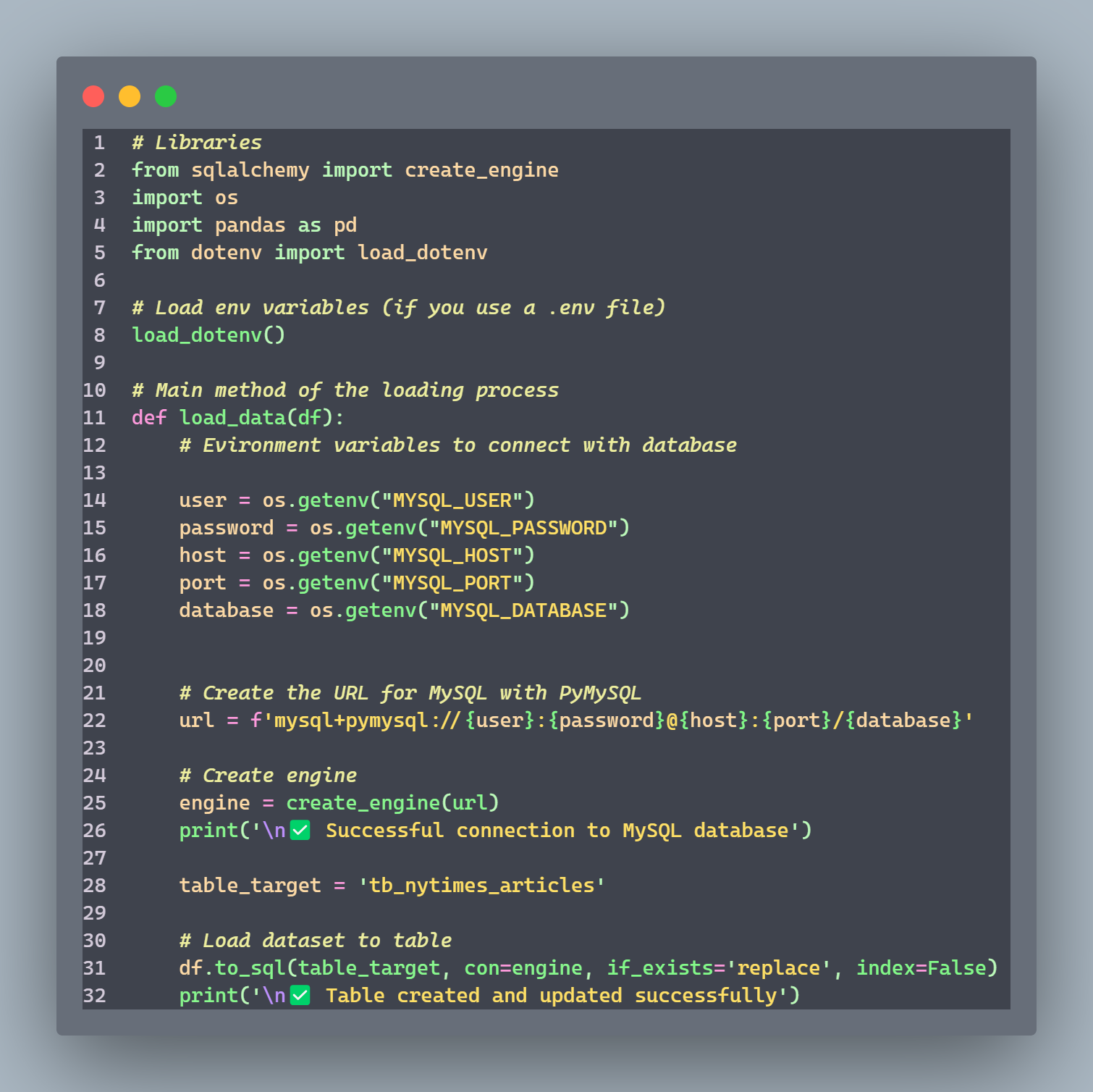
3. Load (load.py)
Establishes connection with MySQL database
Loads transformed data into a table named 'tb_nytimes_articles'
Allows replacing existing data in the table
NYT Articles ETL Pipeline
This project implements an ETL (Extract, Transform, Load) pipeline to fetch, process, and store articles from The New York Times API.
1. Extract (extract.py)
Makes requests to the New York Times API
Allows searching articles by keyword
Implements API rate limiting (12 seconds between requests)
Returns a list of JSONs containing article information
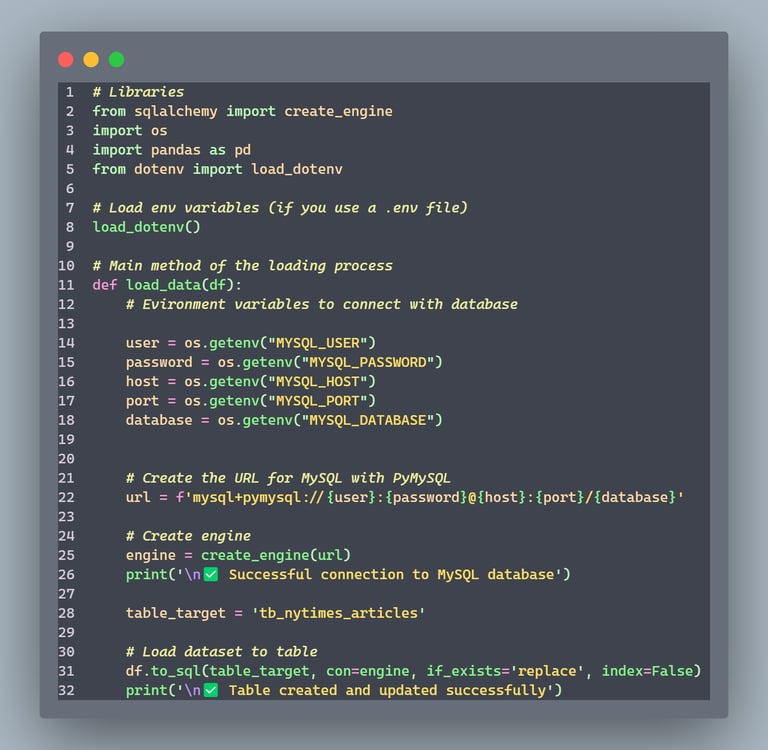
3. Load (load.py)
Establishes connection with MySQL database
Loads transformed data into a table named 'tb_nytimes_articles'
Allows replacing existing data in the table
Solutions
Transforming data into effective enterprise decisions.
InnovaTION
TECHNOLOGY
© 2024. All rights reserved.